BS Computer Science
Sir Syed University of Engineering and Technology — CGPA 3.54
Syed Muhammad Mehmam — AI Engineer with 3+ years of production experience in LLMs, RAG pipelines, LangGraph agents, and Computer Vision. I built a healthcare intelligence platform processing 500+ sessions/month and reduced documentation time by 60%.

3+ years building production AI systems for healthcare, manufacturing, and enterprise clients. I specialize in making LLMs reliable, observable, and cost-efficient at scale.
At Xloop Digital Services, I built a healthcare intelligence platform processing 500+ clinical sessions per month — reducing documentation time by 60%. I also optimized a diarization pipeline from 17 minutes to 5 minutes using FastWhisper, and built a real-time factory surveillance system using YOLOv8.
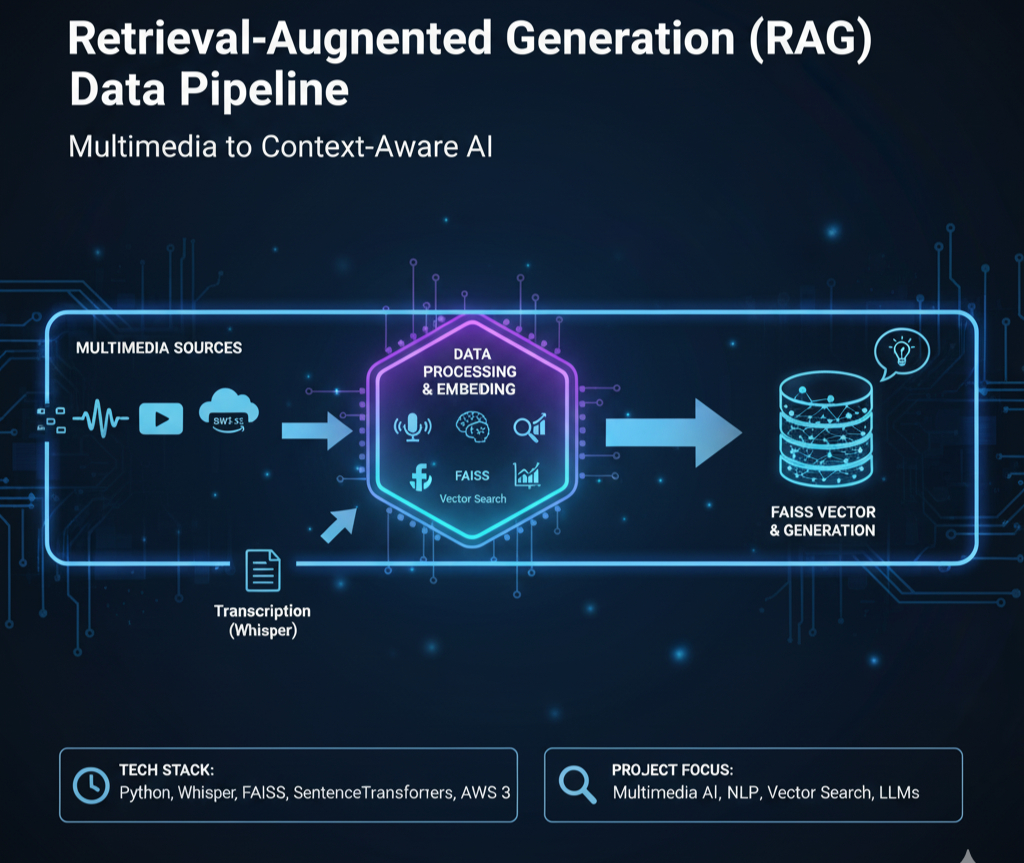
Build RAG pipelines with LangChain, ChromaDB, and Groq LLM.
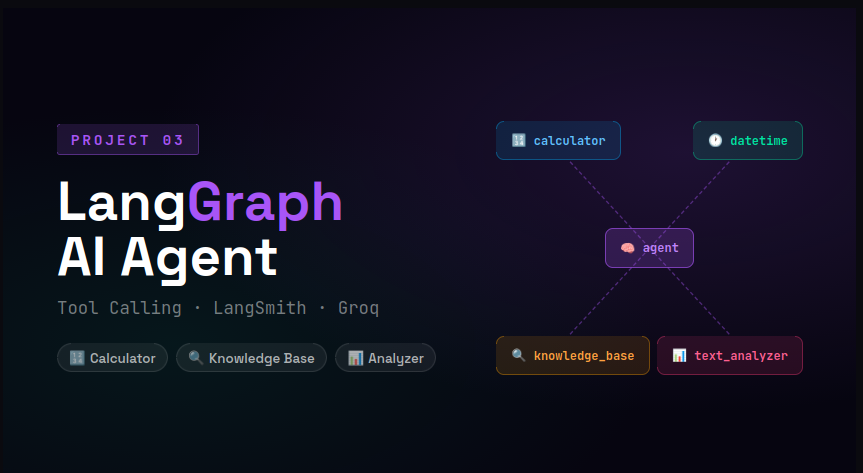
Stateful AI agents with tool calling and LangSmith monitoring.
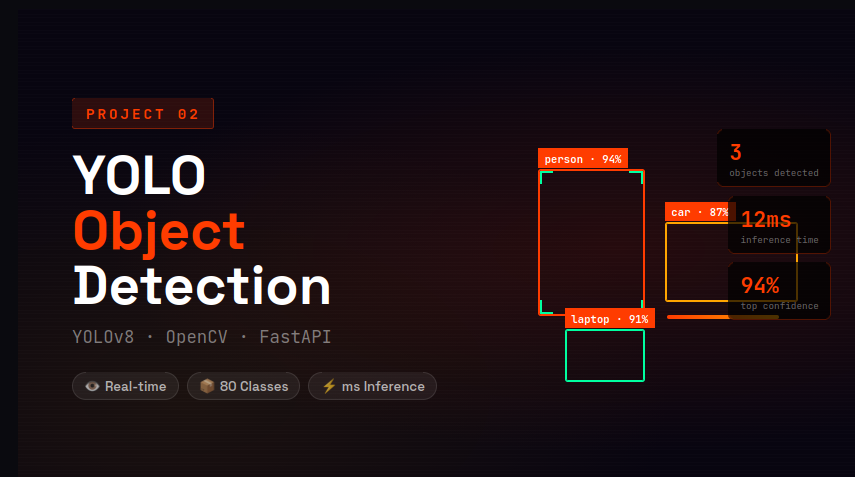
YOLOv8 object detection APIs with OpenCV and FastAPI.
FastAPI backends with Docker, cloud deployment, and monitoring.
Sir Syed University of Engineering and Technology — CGPA 3.54
OCR pipelines, time-series forecasting, predictive models at ArtisticMilliners.
LangChain, LangGraph, LangSmith, YOLOv8, RAG pipelines at Xloop Digital Services.
Freelance AI projects — LangGraph agents, RAG chatbots, Computer Vision APIs.
Production-ready AI solutions — not just prototypes
Chat with your own documents — PDFs, manuals, knowledge bases. Powered by LangChain + ChromaDB with source-cited answers.
Stateful agents that reason, call tools, and execute multi-step workflows automatically using LangGraph with conditional routing.
Real-time object detection systems using YOLOv8 — people, vehicles, custom objects — deployed as a production FastAPI.
A proven, end-to-end process for delivering production AI solutions.
Deep dive into your business needs, data, and desired outcomes.
Selecting optimal LLMs and designing RAG or agentic architectures.
Rapid, iterative building with production-grade documented code.
API deployment, LangSmith monitoring, and handover with full docs.
Production-ready AI systems with full source code, documentation, and live demo videos.
Core strengths across LLM engineering, computer vision, and production AI systems.
LangChain, ChromaDB, Groq, Sentence Transformers — building document chatbots with source-cited answers.
Stateful agent graphs with conditional routing, tool calling, memory, and LangSmith production monitoring.
YOLOv8, OpenCV, FastWhisper — real-time detection APIs and audio processing pipelines.
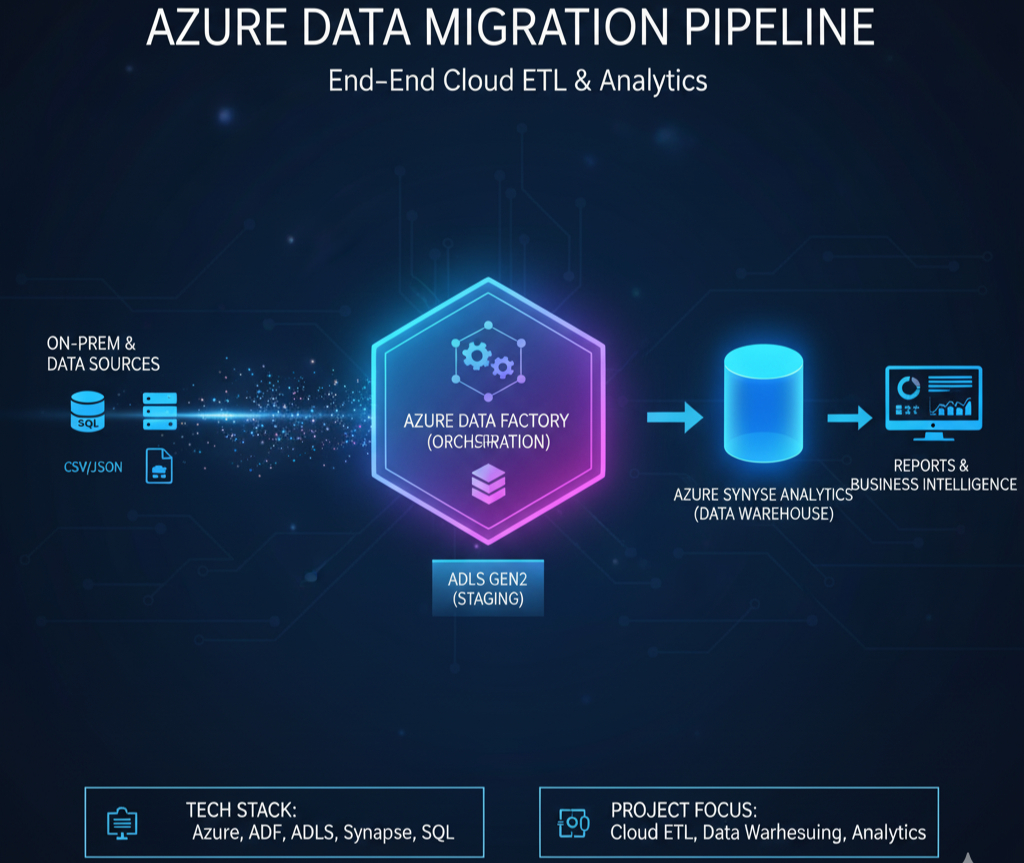
FastAPI, Python, Docker, AWS S3, Azure — deploying and monitoring AI systems at scale.
Also: PostgreSQL, Git, LangSmith, Hugging Face, Azure AI, AWS Bedrock, and data quality frameworks.
View my resume or download the PDF.
Production experience — not just tutorials and demos.
Need a RAG chatbot, LangGraph agent, or Computer Vision API? Share your use case and I'll get back within 24–48 hours.
For any inquiries, please contact me via email.
For engagements, collaborations, and consulting.
Email is best for initial scoping or use LinkedIn.
Happy to schedule a call after your message.
Remote — Worldwide
Replies within 12–24 hours (business days)